

Kubernetes API详解
Kubernetes API概述
Kubernetes API是集群系统中的重要组成部分,Kubernetes中各种资源(对象)的数据都通过该API接口被提交到后端的持久化存储(etcd)中,Kubernetes集群中的各部件之间通过该API接口实现解耦合,同时Kubernetes集群中一个重要且便捷的管理工具kubectl也是通过访问该API接口实现其强大的管理功能的。Kubernetes API中的资源对象都拥有通用的元数据,资源对象也可能存在嵌套现象,比如在一个Pod里面嵌套多个Container。创建一个API对象是指通过API调用创建一条有意义的记录,该记录一旦被创建,Kubernetes就将确保对应的资源对象会被自动创建并托管维护。
apiVersion
apiVersion表明API的版本号,当前版本默认只支持v1。
kind
kind表明对象有以下三大类别。
(1)对象(objects):代表系统中的一个永久资源(实体),例如Pod、RC、Service、Namespace及Node等。通过操作这些资源的属性,客户端可以对该对象进行创建、修改、删除和获取操作。
(2)列表(list):一个或多个资源类别的集合。所有列表都通过items域获得对象数组,例如PodLists、ServiceLists、NodeLists。大部分被定义在系统中的对象都有一个返回所有资源集合的端点,以及零到多个返回所有资源集合的子集的端点。某些对象有可能是单例对象(singletons),例如当前用户、系统默认用户等,这些对象没有列表。
(3)简单类别(simple):该类别包含作用在对象上的特殊行为和非持久实体。该类别限制了使用范围,它有一个通用元数据的有限集合,例如Binding、Status。
Metadata
Metadata是资源对象的元数据定义,是集合类的元素类型,包含一组由不同名称定义的属性。在Kubernetes中每个资源对象都必须包含以下3种Metadata。
(1)namespace:对象所属的命名空间,如果不指定,系统则会将对象置于名为default的系统命名空间中。
(2)name:对象的名称,在一个命名空间中名称应具备唯一性。
(3)uid:系统为每个对象都生成的唯一ID,符合RFC 4122规范的定义。
此外,每种对象都还应该包含以下几个重要元数据。
(1)labels:用户可定义的“标签”,键和值都为字符串的map,是对象进行组织和分类的一种手段,通常用于标签选择器,用来匹配目标对象。
(2)annotations:用户可定义的“注解”,键和值都为字符串的map,被Kubernetes内部进程或者某些外部工具使用,用于存储和获取关于该对象的特定元数据。
(3)resourceVersion:用于识别该资源内部版本号的字符串,在用于Watch操作时,可以避免在GET操作和下一次Watch操作之间造成的信息不一致,客户端可以用它来判断资源是否改变。该值应该被客户端看作不透明,且不做任何修改就返回给服务端。客户端不应该假定版本信息具有跨命名空间、跨不同资源类别、跨不同服务器的含义。
(4)creationTimestamp:系统记录创建对象时的时间戳,符合RFC3339规范。
(5)deletionTimestamp:系统记录删除对象时的时间戳,符合RFC3339规范。
(6)selfLink:通过API访问资源自身的URL,例如一个Pod的link可能是“/api/v1/namespaces/ default/pods/frontend-o8bg4”。
spec
spec是集合类的元素类型,用户对需要管理的对象进行详细描述的主体部分都在spec里给出,它会被Kubernetes持久化到etcd中保存,系统通过spec的描述来创建或更新对象,以达到用户期望的对象运行状态。spec的内容既包括用户提供的配置设置、默认值、属性的初始化值,也包括在对象创建过程中由其他相关组件(例schedulers、auto-scalers)创建或修改的对象属性,比如Pod的Service IP地址。如果spec被删除,那么该对象将会从系统中删除。
API Groups(API组)
为了更容易对API进行扩展,Kubernetes使用API Groups(API组)进行标识。API Groups以REST URL中的路径进行定义。当前支持两类API groups。
Core Groups(核心组),也可以称之为Legacy Groups,作为Kubernetes最核心的API,其特点是没有“组”的概念,例如“v1”,在资源对象的定义中表示“apiVersion:v1”。
具有分组信息的API,以/apis/$GROUP_NAME/$VERSIONURL路径进行标识,在资源对象的定义中表示为“apiVersion:$GROUP_NAME/$VERSION”,例如:“apiVersion:
batch/v1”“apiVersion: extensions:v1beta1”“apiVersion: apps/v1beta1”等,详细的API列表请参见官网https://kubernetes.io/docs/reference,目前根据Kubernetes的不同版本有不同的API说明页面。
如果要启用或禁用特定的API组,则需要在API Server的启动参数中设置--runtime-config进行声明,例如,--runtime-config=batch/v2alpha1表示启用API组“batch/v2alpha1”;也可以设置--runtimeconfig=batch/v1=false表示禁用API组“batch/v1”。多个API组的设置以逗号分隔。在当前的API Server服务中,DaemonSets、Deployments、HorizontalPodAutoscalers、Ingress、Jobs和ReplicaSets所属的API组是默认启用的。
声明式 API结构
在 Kubernetes 项目中,一个 API 对象在 Etcd 里的完整资源路径,是由:Group(API 组)、Version(API 版本)和 Resource(API 资源类型)三个部分组成的。
通过这样的结构,整个 Kubernetes 里的所有 API 对象,实际上就可以用如下的树形结构表示出来:
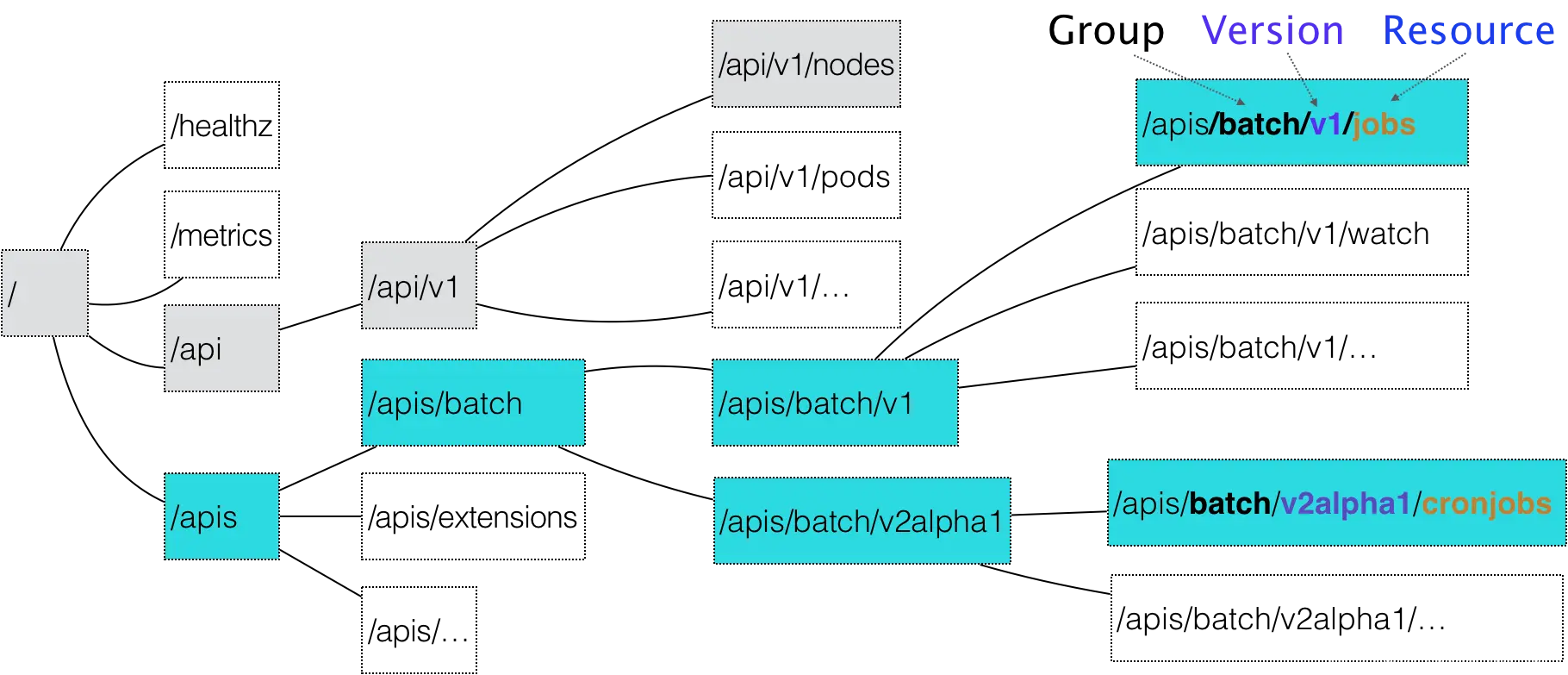

当我们提交了这个 YAML 文件之后,Kubernetes 就会把这个 YAML 文件里描述的内容,转换成 Kubernetes 里的一个 CronJob 对象。那么,Kubernetes 是如何对 Resource、Group 和 Version 进行解析,从而在 Kubernetes 项目里找到 CronJob 对象的定义呢?
首先,Kubernetes 会匹配 API 对象的组
需要明确的是,对于 Kubernetes 里的核心 API 对象,比如:Pod、Node 等,是不需要 Group 的(即:它们的 Group 是“”)。所以,对于这些 API 对象来说,Kubernetes 会直接在 /api 这个层级进行下一步的匹配过程。
而对于 CronJob 等非核心 API 对象来说,Kubernetes 就必须在 /apis 这个层级里查找它对应的 Group,进而根据“batch”这个 Group 的名字,找到 /apis/batch。不难发现,这些 API Group 的分类是以对象功能为依据的,比如 Job 和 CronJob 就都属于“batch” (离线业务)这个 Group。
然后,Kubernetes 会进一步匹配到 API 对象的版本号。
对于 CronJob 这个 API 对象来说,Kubernetes 在 batch 这个 Group 下,匹配到的版本号就是 ****v2alpha1。在 Kubernetes 中,同一种 API 对象可以有多个版本,这正是 Kubernetes 进行 API 版本化管理的重要手段。这样,比如在 CronJob 的开发过程中,对于会影响到用户的变更就可以通过升级新版本来处理,从而保证了向后兼容。
最后,Kubernetes 会匹配 API 对象的资源类型。
在前面匹配到正确的版本之后,Kubernetes 就知道,我要创建的原来是一个 /apis/batch/v2alpha1 下的 CronJob 对象。这时候,APIServer 就可以继续创建这个 CronJob 对象了。为了方便理解,我为你总结了一个如下所示流程图来阐述这个创建过程:
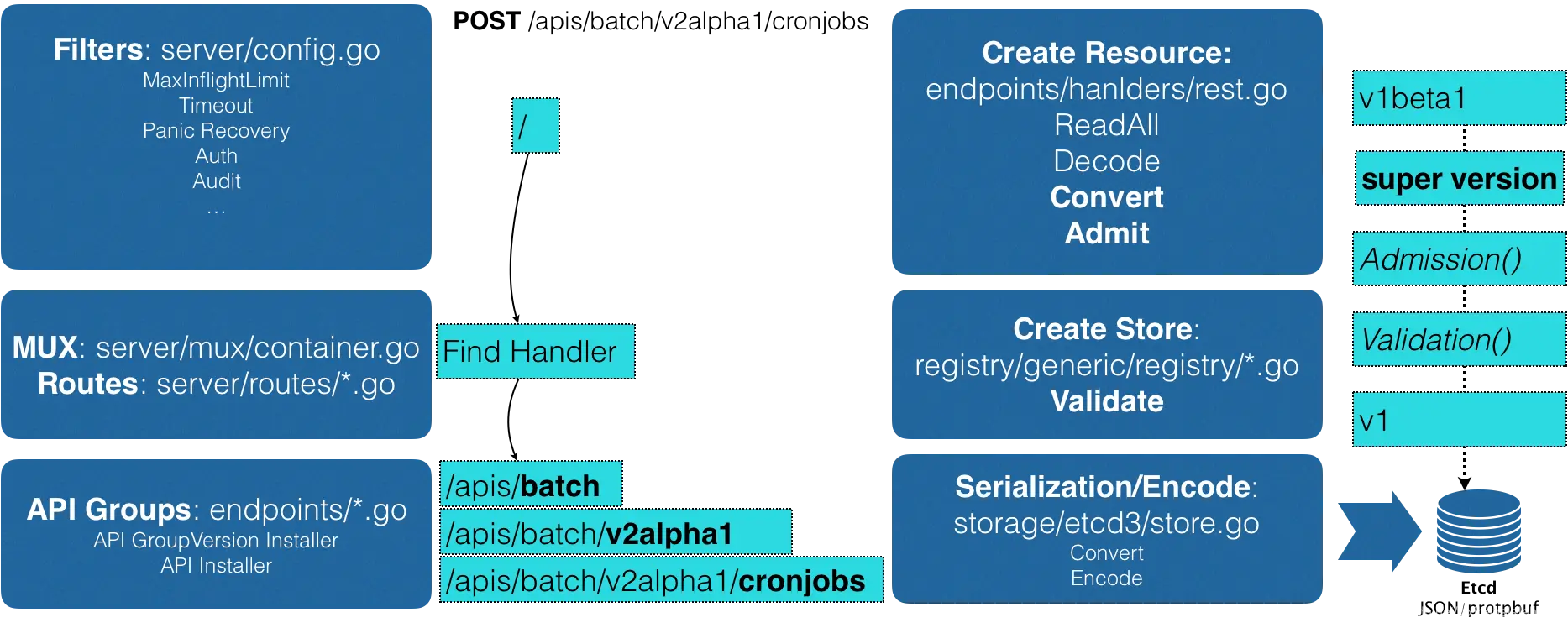
首先,当我们发起了创建 CronJob 的 POST 请求之后,我们编写的 YAML 的信息就被提交给了 APIServer。 而 APIServer 的第一个功能,就是过滤这个请求,并完成一些前置性的工作,比如授权、超时处理、审计等。
然后,请求会进入 MUX 和 Routes 流程。如果你编写过 Web Server 的话就会知道,MUX 和 Routes 是 APIServer 完成 URL 和 Handler 绑定的场所。而 APIServer 的 Handler 要做的事情,就是按照我刚刚介绍的匹配过程,找到对应的 CronJob 类型定义。而在这个过程中,APIServer 会进行一个 Convert 工作,即:把用户提交的 YAML 文件,转换成一个叫作 Super Version 的对象,它正是该 API 资源类型所有版本的字段全集。这样用户提交的不同版本的 YAML 文件,就都可以用这个 Super Version 对象来进行处理了。
接下来,APIServer 会先后进行 Admission() 和 Validation() 操作。比如,我在上一篇文章中提到的 Admission Controller 和 Initializer,就都属于 Admission 的内容。而 Validation,则负责验证这个对象里的各个字段是否合法。这个被验证过的 API 对象,都保存在了 APIServer 里一个叫作 Registry 的数据结构中。也就是说,只要一个 API 对象的定义能在 Registry 里查到,它就是一个有效的 Kubernetes API 对象。
最后,APIServer 会把验证过的 API 对象转换成用户最初提交的版本,进行序列化操作,并调用 Etcd 的 API 把它保存起来。
由此可见,声明式 API 对于 Kubernetes 来说非常重要。所以,APIServer 这样一个在其他项目里“平淡无奇”的组件,却成了 Kubernetes 项目的重中之重。它不仅是 Google Borg 设计思想的集中体现,也是 Kubernetes 项目里唯一一个被 Google 公司和 RedHat 公司双重控制、其他势力根本无法参与其中的组件。
此外,由于同时要兼顾性能、API 完备性、版本化、向后兼容等很多工程化指标,所以 Kubernetes 团队在 APIServer 项目里大量使用了 Go 语言的代码生成功能,来自动化诸如 Convert、DeepCopy 等与 API 资源相关的操作。这部分自动生成的代码,曾一度占到 Kubernetes 项目总代码的 20%~30%。这也是为何,在过去很长一段时间里,在这样一个极其“复杂”的 APIServer 中,添加一个 Kubernetes 风格的 API 资源类型,是一个非常困难的工作。
不过,在 Kubernetes v1.7 之后,这个工作就变得轻松得多了。这,当然得益于一个全新的 API 插件机制:CRD。CRD 的全称是 Custom Resource Definition。顾名思义,它指的就是,允许用户在 Kubernetes 中添加一个跟 Pod、Node 类似的、新的 API 资源类型,即:自定义 API 资源。
自定义 API 资源
为 Kubernetes 添加一个名叫 Network 的 API 资源类型
它的作用是,一旦用户创建一个 Network 对象,那么 Kubernetes 就应该使用这个对象定义的网络参数,调用真实的网络插件,比如 Neutron 项目,为用户创建一个真正的“网络”。这样,将来用户创建的 Pod,就可以声明使用这个“网络”了。
这个 Network 对象的 YAML 文件,名叫 example-network.yaml,它的内容如下所示:
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.0.0/16"
gateway: "192.168.0.1"
可以看到,我想要描述“网络”的 API 资源类型是 Network;API 组是samplecrd.k8s.io;API 版本是 v1。
那么,Kubernetes 又该如何知道这个 API(samplecrd.k8s.io/v1/network)的存在呢?
其实,上面的这个 YAML 文件,就是一个具体的“自定义 API 资源”实例,也叫 CR(Custom Resource)。而为了能够让 Kubernetes 认识这个 CR,你就需要让 Kubernetes 明白这个 CR 的宏观定义是什么,也就是 CRD(Custom Resource Definition)。
这就好比,你想让计算机认识各种兔子的照片,就得先让计算机明白,兔子的普遍定义是什么。比如,兔子“是哺乳动物”“有长耳朵,三瓣嘴”。所以,接下来,我就先编写一个 CRD 的 YAML 文件,它的名字叫作 network.yaml,内容如下所示:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: networks.samplecrd.k8s.io
spec:
group: samplecrd.k8s.io
version: v1
names:
kind: Network
plural: networks
scope: Namespaced
可以看到,在这个 CRD 中,我指定了“group: samplecrd.k8s.io”“version: v1”这样的 API 信息,也指定了这个 CR 的资源类型叫作 Network,复数(plural)是 networks。然后,我还声明了它的 scope 是 Namespaced,即:我们定义的这个 Network 是一个属于 Namespace 的对象,类似于 Pod。
这就是一个 Network API 资源类型的 API 部分的宏观定义了。这就等同于告诉了计算机:“兔子是哺乳动物”。所以这时候,Kubernetes 就能够认识和处理所有声明了 API 类型是“samplecrd.k8s.io/v1/network”的 YAML 文件了。
接下来,我还需要让 Kubernetes“认识”这种 YAML 文件里描述的“网络”部分,比如“cidr”(网段),“gateway”(网关)这些字段的含义。这就相当于我要告诉计算机:“兔子有长耳朵和三瓣嘴”。这时候呢,我就需要稍微做些代码工作了。
评论区